
【スマートものづくりエキスパート育成スクール取組】(4) 文字認識TesseractOCRやってみる

はじめに
前回の記事 【スマートものづくりエキスパート育成スクール取組】(3)カメラ画像を取得 より、OpenCVを使用して、カメラ画像を取得できるようになりました。
SDGsとは持続可能でよりOpenCVでは画像処理を行うことができますが、
まず、画像処理を行わない状態で取得したカメラ画像から文字認識をやってみたらどうなの?
ということで、さっそく文字認識やってみようと思います。
Tesseract OCR
Googleが無料で提供している文字認識ライブラリのTesseract OCRを利用します。
インストールを行っておきます。
また、PythonからOCRを利用可能にするためのモジュールであるPyOCRもインストールしておきます。
(1)画像からテキストを出力する
カメラから取得した画像からテキストを出力し、コンソールに出してみます。
次のようにソースを書きます。
認識させたい文字列であるカード識別番号は英数字のため、読み取り対象言語はEnglishに設定します。
キーボードの”C”キーを押すと、文字認識したテキストをコンソールに出力します。
# -*- coding: utf-8 -*-
#*********************************************************************
# ocr_test1.py
#*********************************************************************
import cv2
import sys
import os
import pyocr
import pyocr.builders
from PIL import Image
# 使用可能なOCRモデルをリストに格納
tools = pyocr.get_available_tools()
# 使用可能なOCRモデルが格納されているリストから取得
tool = tools[0]
# カメラ画像取得(カメラ番号に注意)
cap = cv2.VideoCapture(0) # カメラの接続は1台なので0番
while(True):
# 取得
ret, img = cap.read()
# キャプチャー取得できた場合
if ret == True:
# カメラ画像を表示
cv2.imshow('Image', img) # 「Image」というウインドウ名で表示
# キャプチャーエラーの場合
else:
print("error") # コンソールに「error」と表示
# wait
k = cv2.waitKey(30) & 0xFF # 30msサイクル
# Escキーで終了
if k == 27:
case = 0
break
# cキーが押されたら処理へ
if k == ord('c'):
case = 1 # 認識処理へ
break
# 認識処理
if case == 1:
# 画像からテキストを取得
txt = tool.image_to_string(
Image.fromarray(img), # 画像
lang="eng", # english対応
builder=pyocr.builders.TextBuilder(tesseract_layout=6) # 6 = Assume a single uniform block of text.
)
# コンソールに認識したテキストを出力
print(txt)
# 解放
cap.release()
cv2.destroyAllWindows()
取得したカメラ画像です。認識したい識別番号は「TCS-C0-278」です。

実行し、コンソールに出力されたテキストを見てみます。
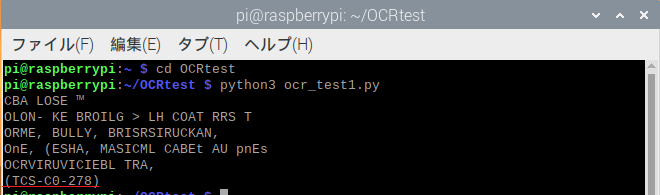
「TCS-C0-278」が出力されており、認識できています。
(2)検出したい文字列を検索する
画像からテキストを出力できたので、検出したい文字列を検索し判定するようにします。
検出したい文字列と完全一致であれば”[–OK–]”を、そうでなければ”[–NG–]”をコンソールに出します。
コマンド引数に判定したい文字を設定します。
# -*- coding: utf-8 -*-
#*********************************************************************
# ocr_test2.py
#*********************************************************************
import cv2
import sys
import os
import pyocr
import pyocr.builders
from PIL import Image
# ★コマンドライン引数
args = sys.argv
# ★コマンドの引数から取得
judg_text = str(args[1]) # 判定文字
# 使用可能なOCRモデルをリストに格納
tools = pyocr.get_available_tools()
# 使用可能なOCRモデルが格納されているリストから取得
tool = tools[0]
# カメラ画像取得(カメラ番号に注意)
cap = cv2.VideoCapture(0) # カメラの接続は1台なので0番
while(True):
# 取得
ret, img = cap.read()
# キャプチャー取得できた場合
if ret == True:
# カメラ画像を表示
cv2.imshow('Image', img) # 「Image」というウインドウ名で表示
# キャプチャーエラーの場合
else:
print("error") # コンソールに「error」と表示
# wait
k = cv2.waitKey(30) & 0xFF # 30msサイクル
# Escキーで終了
if k == 27:
case = 0
break
# cキーが押されたら処理へ
if k == ord('c'):
case = 1 # 認識処理へ
break
# 認識処理
if case == 1:
# 画像からテキストを取得
txt = tool.image_to_string(
Image.fromarray(img), # 画像
lang="eng", # english対応
builder=pyocr.builders.TextBuilder(tesseract_layout=6) # 6 = Assume a single uniform block of text.
)
# コンソールに認識したテキストを出力
print(txt)
# ★判定
if(judg_text in txt): # 認識したテキストの中から判定文字があった場合
print("[--OK--]") # コンソールに「[--OK--]」を表示
else: # 見つからない場合
print("[--NG--]") # コンソールに「[--NG--]」を表示
# 解放
cap.release()
cv2.destroyAllWindows()
先ほどのカードを判定してみます。
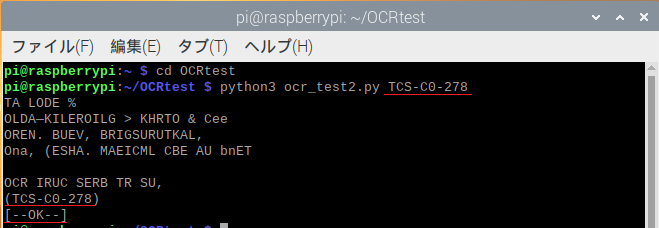
「TCS-C0-278」があり、”[–OK–]”を出力しています。
では、もう少し小さい文字はどうでしょう。

「TCS-CT0-151」を検出してみます。
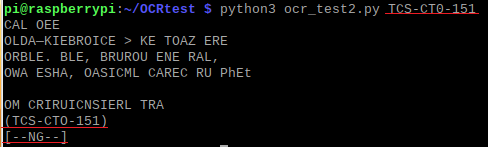
一見、完全一致しているように思えますが、数字の「0」をアルファベットの「O」と認識しているため
NG判定になっています。
カードの種類によって、文字位置が上端のものもあります。

「TCS-CT0-039」を検出してみます。
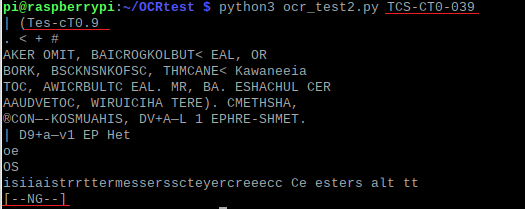
端の方まで認識できていません。
背景色のグレーが濃く、文字サイズが小さいカードもあります。

「TCS-CT0-222」を検出してみます。

まったく認識できませんでした。
わかったこと
大きい文字であれば認識できており、こんなに認識できるとは思っていませんでした。
しかし、文字が小さいと誤認識してしまうようです。
数字の”0″をアルファベットの”O”と誤認識しているものがあり、興味深い結果になりました。
また、画像の端の文字は認識しにくいこともわかりました。
背景色のグレーが濃く、文字が小さいカードはなかなか苦戦しそうです。
まとめ
Tesseract OCRを利用して文字認識を行いました。
今回はまず、画像処理などを行わない生データでOCRをかけてみました。
検出したい文字と完全一致であれば”OK”判定、そうでなければ”NG”判定としましたが、
1文字だけ誤検出しているものもあったので、次回は判定方法を工夫してみたいと思います。