
【スマートものづくりエキスパート育成スクール取組】(10)データ解析

はじめに
これまでに3つの実験を行ってきました。
【スマートものづくりエキスパート育成スクール取組】(7)処理時間の検討
【スマートものづくりエキスパート育成スクール取組】(8)画像フォーマットによる比較
【スマートものづくりエキスパート育成スクール取組】(9)グレースケール化
今回はこれまでの実験データより解析を行います。
解析
OCRで認識した文字の解析を行いました。
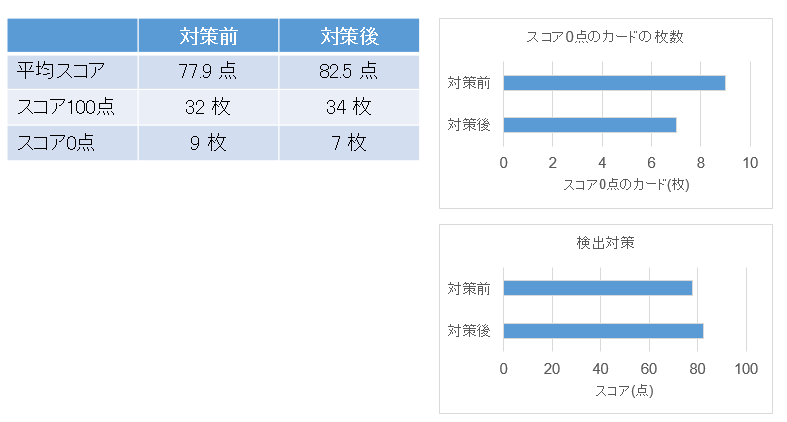
カード44枚のうち約10枚がスコア0点で、
先頭文字「TCS」が検出できていなかったため判定できていませんでした。
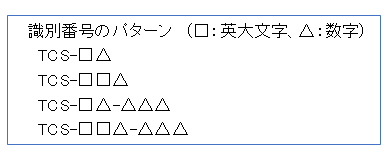
(検出方法は 【スマートものづくりエキスパート育成スクール取組】(5)文字認識の検出をスコア化 より)
OCRでは大文字と小文字を区別しており、「C」と「c」、「S」と「s」、「O」と「o」など
大文字を小文字と誤検出しているものがありました。
また、数字の「0」をアルファベットの「O」「o」と検出しているものもありました。
・大文字である箇所が小文字と検出している
・数字であるはずの箇所が文字または、文字であるはずの箇所が数字と検出している
対策
検出している先頭文字「TCS」の「C」と「S」を小文字でも検出するようにします。
「TCS」、「TcS」、「TCs」、「Tcs」の4パターンです。
結果
スコア0点の数が9枚から7枚に減り、改善されました。
まとめ
これまでの実験データより解析を行い、
大文字と小文字を誤検出しているものがあったり、
数字の「0」をアルファベットの「O」「o」を誤検出しているものがありました。
先頭文字「TCS」の検出で小文字でも検出するようにしたところ、改善することができました。
今回のスマートものづくりエキスパート育成スクールでの取り組みはここまででしたが、
先頭文字「TCS」以外の部分でも改善策はありそうです。
次回はこれまで全10回にわたってご紹介してきた取り組みの振り返りをしたいと思います。