
【スマートものづくりエキスパート育成スクール取組】(5)文字認識の検出をスコア化

はじめに
前回の記事 【スマートものづくりエキスパート育成スクール取組】(4) 文字認識TesseractOCRやってみる より、文字認識をしたところ、一部分を誤検出しているものがありました。
そこで、誤検出の傾向を見て対策を考えるために、スコア化することにしました。
判定方法
まず、撮影した画像から文字認識(OCR)を行い、全ての文字を取得します。
そして、検出した全ての文字の中から判定したい識別番号の先頭文字「TCS」を検索します。
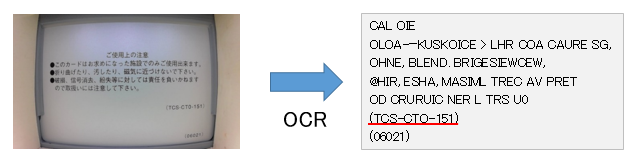
「TCS」が見つかった場合は、「TCS」の文字位置から1文字ずつ識別番号と比較していきます。
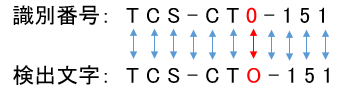
スコアの算出は、識別番号の文字数と、一致した文字数から100点満点のスコアを算出します。
完全一致であれば、スコア100点とします。
例えば、識別番号が「TCS-CT0-151」だった時
もし検出した文字が数字の”0″を大文字の”O”と認識して「TCS-CTO-151」であった場合
識別番号の文字数は11文字で、そのうち1文字が不一致だったため一致した文字数は10文字になります。
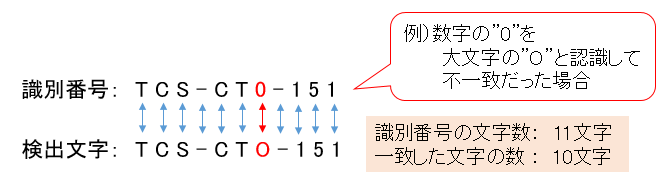
識別番号の文字数と一致した文字数から100点満点のスコアを算出します。
スコアは90.9点となります。

「TCS」が見つからなかった場合はスコア0点とします。
まとめ
誤検出の傾向を見て対策を考えるために、スコア化することを考えました。
この方法でスコアを算出し、検討していきます。
付録
プログラム
# -*- coding: utf-8 -*-
#*********************************************************************
# ocr_test3
# ocr 結果をスコア化
#*********************************************************************
import cv2
import sys
import os
import pyocr
import pyocr.builders
from PIL import Image
# コマンドライン引数
args = sys.argv
# コマンドの引数から取得
judg_text = str(args[1]) # 判定文字
# 使用可能なOCRモデルをリストに格納
tools = pyocr.get_available_tools()
# 使用可能なOCRモデルが格納されているリストから取得
tool = tools[0]
# カメラ画像取得(カメラ番号に注意)
cap = cv2.VideoCapture(0) # カメラの接続は1台なので0番
while(True):
# 取得
ret, img = cap.read()
# キャプチャー取得できた場合
if ret == True:
# カメラ画像を表示
cv2.imshow('Image', img) #「Image」というウインドウ名で表示
# キャプチャーエラーの場合
else:
print("error") # コンソールに「error」と表示
# wait
k = cv2.waitKey(30) & 0xFF # 30msサイクル
# Escキーで終了
if k == 27:
case = 0
break
# cキーが押されたら処理へ
if k == ord('c'):
case = 1 # 認識処理へ
break
# 認識処理
if case == 1:
# 画像からテキストを取得
txt = tool.image_to_string(
Image.fromarray(img), # 画像
lang="eng", # english対応
builder=pyocr.builders.TextBuilder(tesseract_layout=6) # 6 = Assume a single uniform block of text.
)
# コンソールに認識したテキストを出力
print(txt)
# 判定
point =0 # 一致文字数
score = 0 # スコア
pos = txt.find("TCS") # 画像のテキストから"TCS"の位置を取得
if pos > 0: # 位置取得した場合
i = 0
for s in judg_text: # 判定文字を1文字ずつ見ていく
if s == txt[pos+i]: # 検出文字と一致していたら
point += 1 # 一致文字数を加算
i += 1 # 次の文字位置へ
# スコア算出
score = (point / len(judg_text)) * 100 # 100点満点にする(一致した文字数/識別番号の文字数 ×100)
score = round(score,2) # 小数点以下2桁にする
# コンソールにスコアを出力
print("スコア: " + str(score))
# 解放
cap.release()
cv2.destroyAllWindows()