
【スマートものづくりエキスパート育成スクール取組】(6)文字認識の処理時間

はじめに
前回の記事 【スマートものづくりエキスパート育成スクール取組】(5)文字認識の検出をスコア化 より、誤検出の傾向を見て対策を考えるためにスコア化するようにしました。
今回は処理時間の計測を追加します。
また、取得した結果データを解析しやすいように工夫します。
処理時間
作業者がカードに記載されている識別番号を目視するのにかかる時間は5秒程度です。
実際の工程に投入した際に、OCRの処理に時間がかかることによって作業効率を下げたくありません。
取得した画像からOCRを行い、文字列を取得するまでにかかる時間を計測することにします。
次のようにプログラムを追加します。
# ★処理時間計測開始
start = time.time()
# 画像からテキストを取得
txt = tool.image_to_string(
Image.fromarray(img), # 撮影画像
lang="eng", # english対応
builder=pyocr.builders.TextBuilder(tesseract_layout=6) # 6 = Assume a single uniform block of text.
)
# ★処理時間計測終了
elapsed_time = time.time() - start
# ★処理時間算出
elapsed_time = round(elapsed_time,2) # 小数点以下2桁にする結果データ取得方法
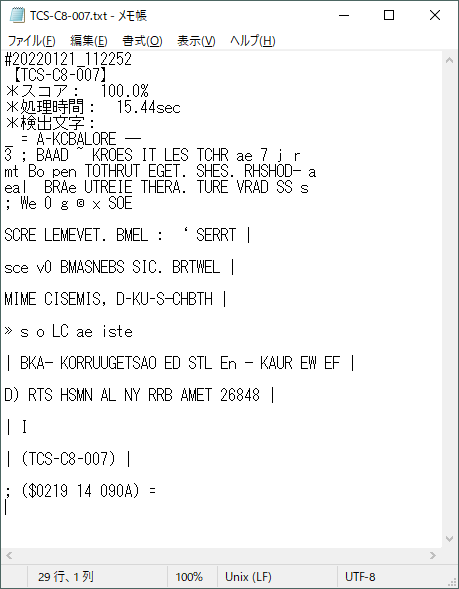
テキストファイルに日付、判定する文字、スコア、処理時間、検出した文字を保存するようにします。
テキストファイル名は、検出したい文字とします。
結果データ集計方法
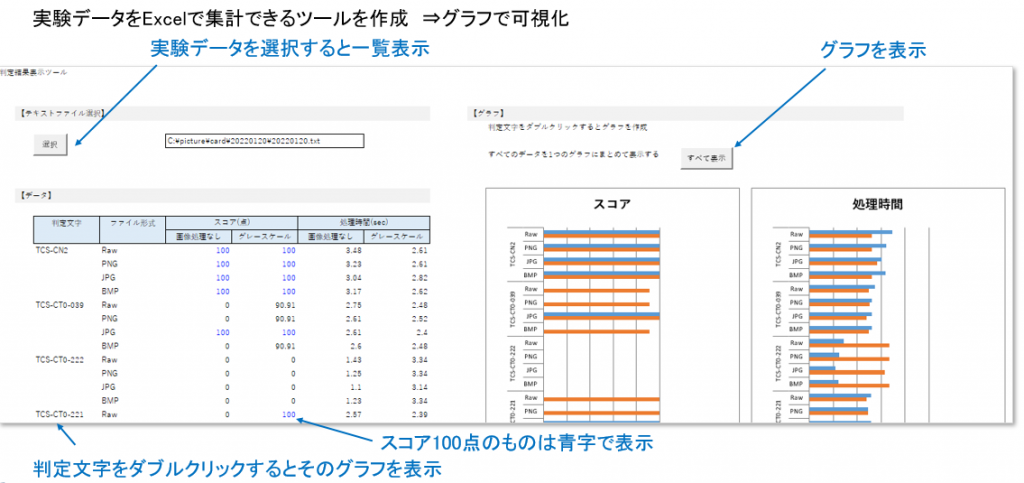
カード1枚ずつの取得データから結果を見ていくのは効率が悪いので、
取得した実験データをExcelで集計できるツールを作成しました。
結果をグラフで可視化できます。
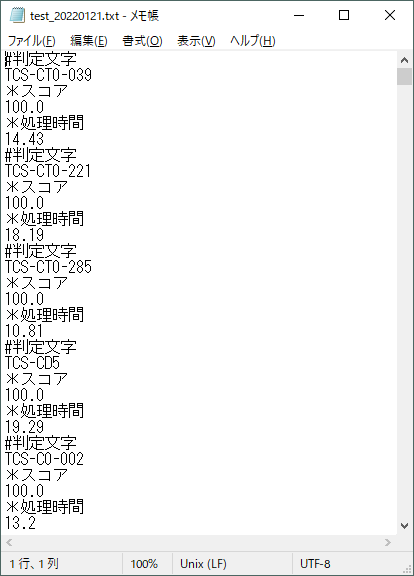
このツールで集計するために、1つのテキストファイルにまとめて保存するようにします。
判定する文字、スコア、処理時間をまとめて保存します。
テキストファイル名は、保存先フォルダ名と同じにしています。
このテキストファイルをツールで読み込むと、結果が表示されます。
結果
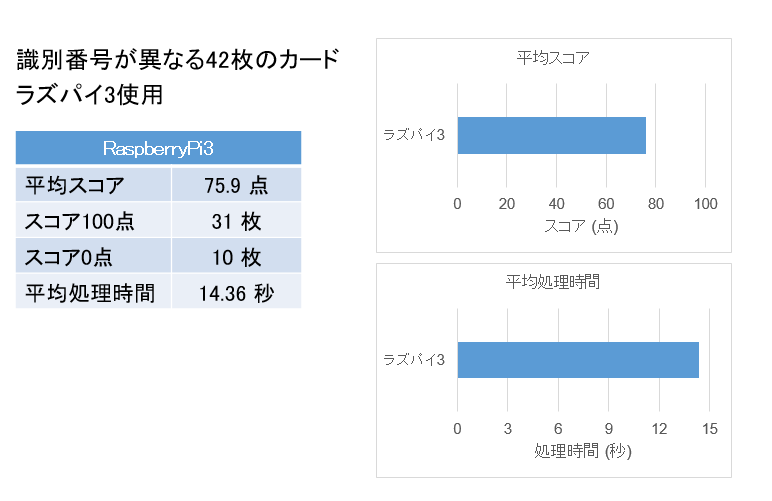
ラズパイ3を使用して、識別番号が異なる42枚のカードで実験したところ、
平均処理時間は14.36秒かかっていることがわかりました。
まとめ
OCRの処理にかかる時間の目標は5秒以下ですが、
今回の実験で処理に15秒近くかかっていることがわかりました。
次回からは処理時間を短縮することを考慮しながら、条件を選定していきます。
付録
プログラム
# -*- coding: utf-8 -*-
import cv2
import sys
import os
import pyocr
import pyocr.builders
from PIL import Image
import time
import datetime
# コマンドライン引数
args = sys.argv
# コマンドの引数から取得
folderName = str(args[1]) # 保存先フォルダ名
judg_text = str(args[2]) # 判定文字
# 使用可能なOCRモデルをリストに格納
tools = pyocr.get_available_tools()
# 使用可能なOCRモデルが格納されているリストから取得
tool = tools[0]
# カメラ画像取得(カメラ番号に注意)
cap = cv2.VideoCapture(0) # カメラの接続は1台なので0番
while(True):
# 取得
ret, img = cap.read()
# キャプチャー取得できた場合
if ret == True:
# カメラ画像を表示
cv2.imshow('Image', img) #「Image」というウインドウ名で表示
# キャプチャーエラーの場合
else:
print("error") # コンソールに「error」と表示
# wait
k = cv2.waitKey(30) & 0xFF # 30msサイクル
# Escキーで終了
if k == 27:
case = 0
break
# cキーが押されたら処理へ
if k == ord('c'):
case = 1 # 認識処理へ
break
# 認識処理
if case == 1:
# まとめて保存するフォルダを作成
root = root + folderName + "/" # フォルダ保存パス
if os.path.exists(root) == False: # フォルダが存在していなければ
os.mkdir(root) # フォルダを作成
root_comb = root # パスを控えておく(まとめテキスト作成のため)
# そのフォルダの中に判定文字名のフォルダを作成
root = root + judg_text + "/" # フォルダ保存パス
if os.path.exists(root) == False: # フォルダが存在していなければ
os.mkdir(root) # フォルダを作成
# 現在時刻取得
now = datetime.datetime.now()
# 処理時間計測開始
start = time.time()
# 画像からテキストを取得
txt = tool.image_to_string(
Image.fromarray(img), # 画像
lang="eng", # english対応
builder=pyocr.builders.TextBuilder(tesseract_layout=6) # 6 = Assume a single uniform block of text.
)
# 処理時間計測終了
elapsed_time = time.time() - start
# 処理時間算出
elapsed_time = round(elapsed_time,2) # 小数点以下2桁にする
# 判定
point =0 # 一致文字数
score = 0 # スコア
pos = txt.find("TCS") # 画像のテキストから"TCS"の位置を取得
if pos > 0: # 位置取得した場合
i = 0
for s in judg_text: # 判定文字を1文字ずつ見ていく
if s == txt[pos+i]: # 検出文字と一致していたら
point += 1 # 一致文字数を加算
i += 1 # 次の文字位置へ
# スコア算出
score = (point / len(judg_text)) * 100 # 100点満点にする(一致した文字数/識別番号の文字数 ×100)
score = round(score,2) # 小数点以下2桁にする
# テキストに保存
# txtファイルパス
txtPath = root + judg_text + ".txt" # 判定文字名.txt
# txtファイルに書き込み
f = open(txtPath,'a',encoding='UTF-8') # 新規txtファイルの作成
# 現在時刻
f.write('#')
f.write(now.strftime('%Y%m%d_%H%M%S\n')) # 現在時刻
# 判定文字
f.write('【')
f.write(judg_text) # 判定文字
f.write('】\r\n')
f.write('*スコア: ')
f.write(str(score)) # スコア結果
f.write('%\n') # %
f.write('*処理時間: ')
f.write(str(time)) # 処理時間結果
f.write('sec\n') # sec
f.write('*検出文字:\n')
f.write(txt) # 検出文字
# 閉じる
f.close()
# テキストに保存 (まとめ)
# txtファイルパス
txtPath = root_comb + folderName + ".txt" # フォルダ名.txt
# txtファイルに書き込み
f = open(txtPath,'a',encoding='UTF-8') # 新規txtファイルの作成(既に作成済なら追加)
# 判定文字
f.write('#判定文字\n')
f.write(judg_text) # 判定文字
f.write('\n')
f.write('*認識率\n')
f.write(str(score)) # スコア結果
f.write('\n')
f.write('*処理時間\n')
f.write(str(time)) # 処理時間結果
f.write('\n')
# 閉じる
f.close()
# 解放
cap.release()
cv2.destroyAllWindows()